DBT
dbt is an open-source command-line tool that enables data transformation and modeling in a structured and efficient manner. It allows data engineers and analysts to define and manage the data transformation pipeline using SQL queries. With dbt, you can write modular and reusable SQL code, called "models," which define the transformations required to convert raw data into structured and analysis-ready data. These models can be organized, tested, and documented within the dbt framework. dbt leverages the power of SQL and provides a layer of abstraction on top of the data warehouse, making it easier to develop, test, and maintain complex data transformations. It promotes best practices such as version control, testing, and documentation, enabling collaborative and maintainable data modeling workflows. dbt integrates with various data warehouses and can be used in conjunction with other data tools and orchestration platforms to create a robust and reliable data pipeline.
Why DBT
The killer feature of dbt is abstracting away the complexities and leaving only the modeling as a complexity. It gives data analysts a tool to work with data and doing it in the right way. What are those ways
- Version control
- Dev-Ops pipelines (CI/CD)
- Referneces
- Documentation And a host of other features.
This means your data engineers time can be released
DML
Data Manipulation Language (DML) is a class of SQL statements that are used to query, edit, add and delete row-level data from database tables or views. The main DML statements are SELECT, INSERT, DELETE, and UPDATE.
DDL
Data Definition Language (DDL) is a group of SQL statements that you can execute to manage database objects, including tables, views, and more. Using DDL statements, you can perform powerful commands in your database such as creating, modifying, and dropping objects. DDL commands are usually executed in a SQL browser or stored procedure.
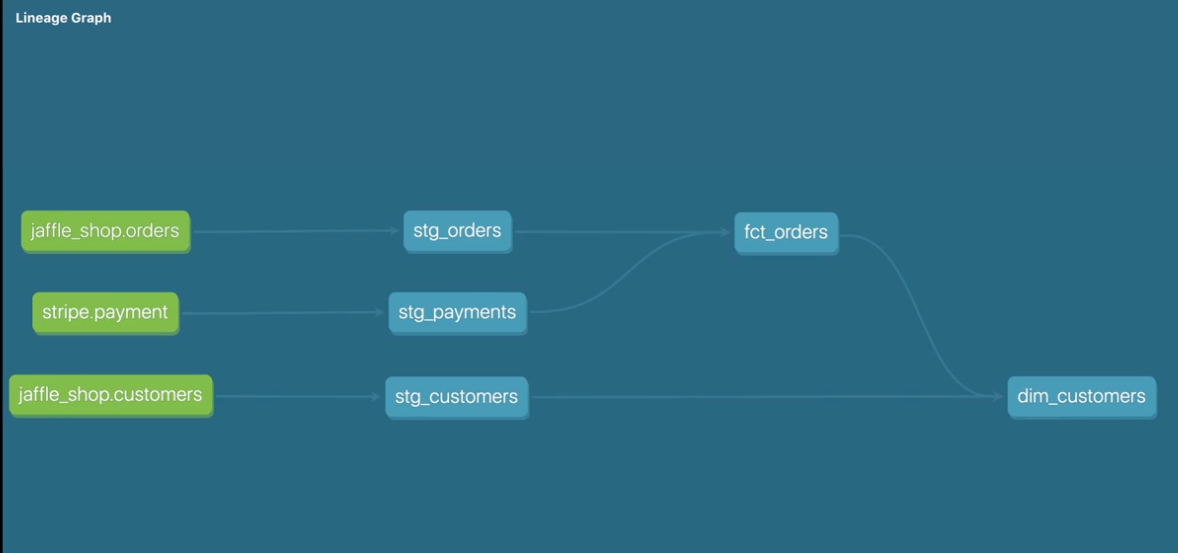
Naming conventions
-Sources
- The raw data that has already been loaded staging
- Clean and standarzie the data
- One to one with source Intermdeiate
- Models between sataging and final models
- Always built on staging models Fact
- Things that are ccuring or have occured
Dimension
- People places or things.
- Things that might change.
 See also medallion architecture
See also medallion architecture